
AcuMatch は 本関数群の中核となるユーザー定義関数(自作関数)です。
AcuMatch の 肝と言えるのは、重複するデータをカンマ区切りのテキスト(CSV形式)で拾い上げる点です。
3,8,12,17,24 といったように重複データの存在位置を書き出します。
また、オプション①として、位置ではなくデータそのものを拾い上げることも可能です。その際オプション②のオフセット値を設定することで、対応する項目のデータを拾うことができます。
構文
AcuMatch(検索文字列, 検索範囲, [表示形態], [オフセット値])
AcuMatch(SrcSt As String, BoundAR As Range, Optional hyoujikeitai As Integer = 0, Optional offsetval As Long = 0)
AcuMatchの使い方を、次のテーブルを用いて説明します。
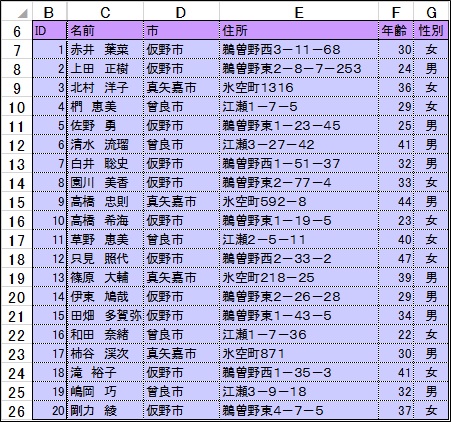
まず、重複する文字列を指定します。ここでは、「鵜曽野東」が含まれるデータを検索することとします。
◇SrcSt(検索文字列)⇒“鵜曽野東”
次にどの範囲から検索するかを指定します。この場合E列ですので、$E$7:$E$26 となります。
◇BoundAR(検索範囲)⇒$E$7:$E$26
式の入力をしてみましょう。
=AcuMatch(“鵜曽野東”,$E$7:$E$26) これだけです。結果 2,5,8,10,14,15,20 と関数を入力したセルに表示されます。
これが、何を表すかというと、”鵜曽野東”という文字列が含まれるセルは、$E$7:$E$26 の範囲(20個のレコード)中の 2番目、5番目、8番目、10番目、14番目、15番目、20番目に存在することを表しています。
さらにオプションを追加して入力してみましょう。
※オプションとは必ずしも入力しなけばならないものではないが、入力した際にはそれに見合った結果を返すものです。
=AcuMatch(“鵜曽野東”,$E$7:$E$26,1,-2) と入れると、上田 正樹,佐野 勇,園川 美香,高橋 希海,伊東 鳩哉,田畑 多賀弥,剛力 綾 と出るはずです。
オプション①( 1 と入れたところ)は該当データのある場所[ 2,5,8,10,14,15,20]ではなく、データそのもので返すことを意味します。オプション②(-2 と入れたところ)はオフセットを表し、検索範囲の列を基準(0)として、-1 なら一つ左の列を参照し、1 なら一つ右の列を参照するものです。
つまり、「鵜曽野東」という地番に住んでいるのは、{上田 正樹,佐野 勇,園川 美香,高橋 希海,伊東 鳩哉,田畑 多賀弥,剛力 綾}となるわけです。
AcuMatchによって、取り出したいデータがカンマ区切りのテキストデータで拾い上げたのはいいが、それをどうやって使うかが、次のポイントとなります。
CSVChoose は セルに書き出されたカンマ区切りテキスト を 配列として読み込み、指定した順番のデータを取り出すものです。
構文
CSVChoose(n番目, 配列値, [抽出形式], [エラー除去])
CSVChoose(n番目 As Double, strArray As String,Optional 抽出形式 As Integer = 0, Optional エラー除去 As Boolean = True) As Variant
=CSVChoose(3, AcuMatchで出したテキストがあるセル番地 ) ⇒ 園川 美香

